
In the world of data analysis, numbers and statistics are no longer the only things we are concerned with. As the field has evolved over the years, we have developed methodology to comprehend a very useful and very prolific type of data: written text.
The challenges of analyzing human text need little introduction. Unstructured, qualitative data like this is unpredictable and does not easily fit into an analysis model, so the need for automation and innovation is great. Once completed, though, text analysis provides a wealth of insights that would otherwise be left uncovered by less advanced approaches like reading the text manually. And from a business perspective, garnering insights from text data like customer or employee feedback allows for more depth of understanding how people are feeling about your company.
Text analytics has a lot of technical elements and we could get super academic about them. But that’s what the Wikipedia article on text mining is for. In this article, we’ve tried to boil the topic down to the elements you care about for the business applications of this technology.
Glossary of text analysis terms
Reading about text analytics can sometimes bring more questions than answers. Here’s our glossary of the more technical terms you might encounter, and what they mean. Some of these are defined more in depth in the sections to come, so we keep it brief here:
- Deep learning: Approach to training AI models that uses artificial neural networks with “deep” layers that can recognize complex patterns in data
- Intent detection: Technique that monitors the set of behaviors that indicate if a person is going to take a certain action, like a purchase
- Keyword extraction: Text analysis technique that identifies keywords, topics, or themes in a text dataset
- Machine learning: Approach to training AI models in which the model learns from training data in order to later be able to extend its competence to unseen data
- Natural language processing (NLP): Computing field concerned with teaching machine algorithms to understand and produce human language as well as we do
- Polarity: Refers to whether a text is considered to be positive or negative in terms of the emotions expressed within it
- Qualitative data: As opposed to quantitative data, this refers to data usually in the form of words and phrases that cannot be expressed numerically
- Rule-based: Describes a type of text analysis that uses predefined rules, keywords, dictionaries, or lexicons to provide a framework for the analysis of the data
- Sentiment analysis: Also called opinion mining, this is a methodology used to measure the polarity of text data
- Text classification: Machine learning technique that takes unstructured text data and assigns predefined categories to it
- Theme: A concept, topic, or pattern of meaning identified in a dataset through text classification
- Unstructured data: In comparison to structured data, this refers to any kind of data that does not fit a predefined model of organization
1. The foundations of text analysis
Text analysis begins with a simple idea: data analysis of a given text dataset. Traditionally, in the academic applications of text mining, this dataset was a static corpus like a book or a database of books. Nowadays, in the business world, datasets are more dynamic and complex, like real-time conversations with customers or incoming contact center tickets.
The ability to analyze large amounts of text at once allows you to do two important things:
- At the document level: You can find patterns, trends, and common features across the entire dataset. This is useful to automate because even if you could read the entire dataset yourself, you’d probably miss the big insights that text analytics would uncover. After all, you’re only human… right?
- At the sub-document, or sentence, level: You can identify relationships between elements such as polarity, sentiment, and intent. This is more fine-grained than the document level and needs a pretty advanced engine to understand natural language quirks like sarcasm, irony, and the overall context of the data.
You can see that there are multiple levels of granularity that can be achieved with text analysis. For something like a literature corpus analysis, you’ll be looking at the document level to find broad patterns across a number of books. For something like customer feedback analysis, you might want to look at the sub-document level to scan for nuances in the text that indicate how the customer felt about a specific product.
Broad analysis at the document level often surfaces insights that you will want to look into further at a more granular level. Take the following amusing example from searching the Google Books Ngram Viewer, which displays word and phrase usages over time:
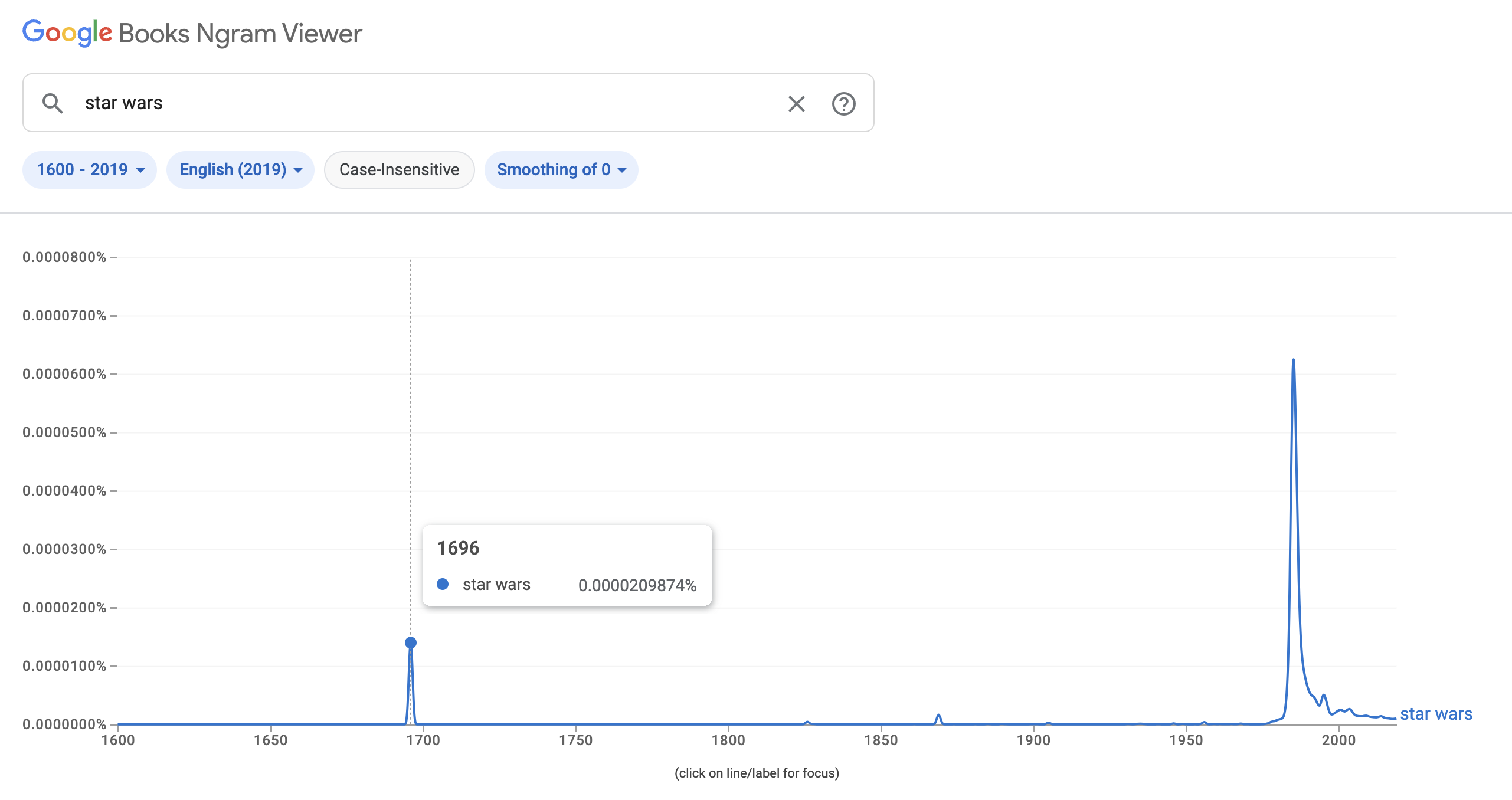
Obviously, we know that Star Wars did not exist in the 1600s, save for some grand conspiracy yet to be revealed. The question then is: What is the relationship between these two words that appeared in this literature at this time? To this end, text analysis can certainly help you answer your initial questions. But at the same time, it digs up more nuggets of information that you might want to ask questions about. In the business world, we refer to this as “learning what you don’t know”. Often, you’ll find that text analytics helps you answer questions you didn’t know you even had.
The ability to find insights that might surprise you and shed light on your blind spots is a big part of how AI comes into play with text analytics software. But first, let’s go over some general text analysis techniques to give you an overview of what text analysis actually is.
2. Text analysis techniques
Conducting text analysis involves many smaller components and techniques that altogether result in the completed data analysis. Let’s take a look at some of these sub-components. Most, if not all, of these processes will be involved in any kind of text analysis you do. And of course, there are multiple approaches to each of these techniques, including with AI, which we’ll see in the next section.
- Text classification: This is a machine learning technique that takes unstructured text data and assigns predefined categories to it. While it relies on user input to define the categories, it is a strong component of text analysis. It can be performed manually, with a human annotator in the loop, or automatically with AI.
- Keyword extraction: This technique identifies keywords, topics, or themes in a text dataset. It is through this method that word clouds are generated. It allows you to easily monitor the frequencies of words or phrases in your dataset.
- Sentiment analysis or opinion mining: Sentiment refers to the emotion or feeling expressed in a text and in particular, the polarity of that emotion. Sentiment analysis is a method of analyzing text data to determine whether a text or part of a text is positive or negative, showing satisfaction or dissatisfaction, containing questions or suggestions, requiring urgent attention or is low priority, and so forth. This is largely used in the business context of text analysis where it is important to understand the voice of the customer.
- Intent detection: Customer intent is the set of behaviors that indicate if a person is going to take a certain action, like a purchase. In the context of text analysis, you might want to know if a customer is at risk of churning and losing loyalty to your brand. Text analysis can pinpoint these early signs of disengagement.
In general, one of the main advantages of text analysis is that you can turn qualitative text data into statistical information. For instance, you could learn that 60% of your customers are talking about the quality of your customer service and of those, 80% wrote comments with a negative polarity. That is an actionable business insight. And all of it relies on the intersection of techniques like text classification, keyword extraction, and sentiment analysis.
Learn more about the voice of the customer
Read our complete guide to the voice of the customer here.
3. Automating text analysis with AI
Modern text analytics has undergone massive transformations with the advancement of AI technology. At its core, the foundations of text analysis are still standing – we’ve just managed to extend this technology to a greater array of use cases. With the expansion of text analytics into business use cases, greater innovation with AI pushes to optimize these processes as much as possible.
Early AI text analysis models were usually rule-based or keyword-based. These approaches use predefined rules, keywords, dictionaries, or lexicons to provide a framework for the analysis of the data. This is how text classification generally works: the rules guide how the algorithm looks for semantic elements to categorize a particular text.
With these models, you run into limitations pretty quickly. Supplying a list of keywords defines, but also limits the problem areas beforehand. It’s like the old saying: “If you only have a hammer, every problem looks like a nail”. In this case, what if there are nails you can’t see? Going back to what we said earlier, you want to learn what you don’t know about your data – especially what you don’t know to look for, too. These models also rely on trained analysts to define rules and keywords, which limits how you might use it at your organization.
So while rule- and keyword-based solutions allow analysts to find what they’re looking for, AI enables everyone – data expert or not – to find what they’re not looking for. This of course is the power of deep learning, machine learning, and Natural Language Processing (NLP).
- Natural Language Processing (NLP): This is a sub-field of computational linguistics that treats text data in the form of natural human language. The objective of NLP from a computing point of view is to develop an algorithm that understands (and in some cases, can produce) human language with the same depth and contextual nuance as a human would. In plain English, we’re trying to get computers to understand language the way we do. NLP is the engine behind Siri, ChatGPT, and most technology that interacts with humans through language.
- Machine learning: This is a technique for training an AI model to learn from data that it is trained with, in order to progressively build on its knowledge or competence and eventually extend its abilities to unseen data. The idea is to create a model smart enough to handle data that it has not seen before. In text analytics, an example of this is a model which can understand the nuances of a specific industry without having seen similar data before. A classic example would be understanding that “sucks” is a good thing if you are analyzing a dataset of reviews for a vacuum.
- Deep learning: This is a sub-field of machine learning that relies on artificial neural networks to learn from data. The idea is that the neural network is built of many layers that allow the model to recognize complex patterns. That’s what the “deep” part means.
Why should you care about all this? Well, knowing how AI contributes to text analysis reveals a lot about the complexity of the task and by extension, the usefulness of AI in modern text analytics. Using AI can support or automate the techniques involved in text analysis that we saw in the previous section:
- Input categorization: You begin here by manually categorizing a few example inputs and then feed the information into the algorithm, which then attempts to build its own rules. A few drawbacks here include the difficulty of properly training the algorithm and the need to regularly update its knowledge with new data.
- Topic detection: In this approach, the algorithm learns by itself without much human input. The algorithm works by looking at simple words and how often they show up alongside other words in the same text input, like a single review or support ticket. It then leverages statistical methods and probability to uncover the main topics mentioned in the text.
- Thematic analysis: Here, the algorithm groups words and phrases together into themes and attempts to understand the meaning behind them. It’s an approach that requires little human input, but the time and effort it takes to set up are rather high.
An important distinction here is between supervised and unsupervised machine learning. As the name suggests, supervised machine learning involves human review to train and correct the algorithm from time to time, while unsupervised machine learning really puts the AI to work. In any cases, the advantages of AI are clear: these algorithms can understand natural language fluidly and accurately, even without training specifically for the context of your business. When we take into account the business considerations of adopting a text analytics software (which we cover in a later section), you will see that setup time and quality of insights play a very important role.
4. Types of text analytics software
Software used for text analytics in the business context generally comes in three forms. Let’s outline the various functionalities, pros, and cons of the big three: customer experience platforms, API-only vendors, and full text analytics solutions:
- Customer experience platforms: These solutions use rule- or keyword-based technology to extract context and meaning from unstructured data, which we went over in a previous section. This approach is accurate and consistently good at recall, but not great in terms of precision or subtle nuances. An ongoing challenge for these solutions is that it has a lengthy implementation and set up process, which means that accuracy issues and blind sports discover later down the road are difficult and take a lot of work to correct. Using a keyword-based solution means you’ll need to plan time to set up your customer verticals. In non-traditional verticals where customers don’t always express themselves in the ways documented in vendor-provided industry vertical libraries and augmented by your specifications, accuracy can suffer.
- API-only vendors: An API is simply a method of helping different softwares communicate with one another. In the world text analytics, it means something else, though. Software that includes text analytics or NLP APIs usually means that there is only a text analytics layer within a wider, more comprehensive text analytics solution. With this layer alone, initial functionality is usually just a few basic features like key topics, categories, and tag clouds. If you choose to go with an API-only solution, you’ll likely need to internally build up the remaining layers for more advanced features and granular insights. See the section below on the “build vs buy” question in text analytics.
- Full text analytics solutions: By leveraging the very latest research in NLP and AI, modern text analytics providers have been able to move away from rules and keywords in favor of more agile, iterative machine learning technologies. One of the biggest advantages of this kind of solution is that it’s less likely to leave you with blind spots. Like we said earlier, rule and keyword-based solutions allow you to find what they’re looking for, but AI enables everyone to find what they’re not looking for. Full text analytics solutions are also much easier to scale. With less setup and configuration required, any increase in the volume of unstructured data from existing feedback sources is easily accommodated – as are new sources, products, and markets.
We’ve been mentioning a few times the fated “build vs buy” question in text analytics in this section. The SaaS industry has evolved a lot in recent years, but so has technology like OpenAI’s GPT that makes potential software buyers wonder if there is a way to build a solution on their own that meets their needs adequately. Let’s dive into this big question in text analytics in the next section.
5. Build or buy text analytics
When considering a text analytics solution at your company, a big question you might have is: Can I build this in-house? It’s a good question. In today’s market, especially with the advances in technologies like GPT, it is a fair option to consider.
Nowadays, with the proliferation of the SaaS industry, software solutions can be deployed much more efficiently than in the past. Building a solution internally involves potentially years of work as your team researches, builds, and trains the model to accurately classify and analyze text data. Just because you can do it doesn’t mean it’s a seamless or user-friendly process, especially for businesses that don’t have the extensive resources needed to support such an endeavor. Compare the efforts involved here with the adoption of a reputable third-party SaaS solution that uses AI and NLP. Fortunately, you don’t need to know the inner workings of any of these solutions to get set up and start making a difference with a strong ROI.
However, choosing a third-party software solution warrants caution as well. Some text analytics solutions used today are still built on rule- and keyword-based models, which are certainly less competitive than AI-based text analytics software. Especially in cases where the solution needs extensive training, in which the existing rules and keywords are layered onto established industry verticals, this may not be the way to go depending on your business needs. This integration is slow and it can take months (and a lot of money) to implement the solution, which kind of nullifies the advantage you get from buying over building.
For more information, we have a larger article on the topic of build vs buy.
Case study: Intelcom builds a data-driven VOC program with Keatext
Keatext gave Intelcom’s team the scalable text analytics they needed to evolve from doing manual VOC reports to championing a robust CX strategy that brings together multiple teams at the organization around a common methodology: using customer insights to drive decision-making.
Quick view:
- The situation: 5000 daily responses from post-delivery and post-return CSAT surveys
- The problem: No data-driven, scalable VOC program to gain insights from open-ended responses
- The solution: Keatext’s strong text analytics and SWOT recommendations formed the foundation for Intelcom’s VOC program
- The impact: Digital transformation of Intelcom’s CX practices, led by the team at Intelcom championing Keatext
Keatext introduced a level of automation and AI-based text analytics that enabled Intelcom’s team to identify the most common concerns, questions, and suggestions from customers. Using Keatext for this purpose enables Intelcom to automatically categorize cases and route them to the most appropriate business unit. This has a high ROI for the team, directly impacting responsiveness and helping them to better structure their service offerings.
Read the full case study here.
6. What to consider in a text analytics solution
For businesses operating in stable industries that don’t see much variation in customer feedback, the traditional rule-based approach to text analytics might be adequate. But for businesses that oversee large multichannel networks of customer feedback, a more sophisticated AI-based solution is the way to go – one that is built around continuous improvement, adaptation, and agility.
The following criteria are a set of guidelines for what to consider in a text analytics platform. The best software will be able to handle all of these criteria and provide a robust, actionable analysis for your business.
- Predictive analytics: Can you get recommendations on what to improve in the customer or employee experience that have quantifiable ROI?
- Reporting: Does the solution provide dashboarding, advanced data visualization, and UX optimized for business users and roles to support enterprise-level reporting needs?
- Richness of the analysis: Is the language analysis deep and rich, and does it detect categories such as questions and suggestions made by customers?
- Explainability: Is it easy to understand the logic and context behind the analysis and back decisions with quantifiable support arguments?
- AI cognition: What is the level of effort required to enable the AI model to identify relevant topics to monitor and report on?
- Deep dive: Can a user explore insights at different levels of aggregation and granularity?
- Labeling: Are themes, intents, and sentiments identified, clustered, and labeled automatically?
- Sub-document level analysis: Is it possible to identify all sentiments that might occur in a single text feedback?
- Robustness: Does the model detect new, unforeseen situations or issues in the customer experience? Can it answer the question “tell me what I dont know”?
- Omnichannel integration: Does the system integrate seamlessly with multiple data sources that support the most common CX and EX use cases?
- Self-serve free trial: Is it possible to test the platform in a self serve mode? Does it require setup and customization beforehand?
For an overview of text analytics providers and their platform offerings, you can view our competitive analysis. It takes the criteria above and grades these solutions (including our own) based on how well they fulfill them.
Subscribe to the Keatext blog for more insights on text analysis
7. Getting executive buy-in for text analytics
Securing executive buy-in is the last item we’ll cover in this post. Consider the potential return on investment from your approach to text analytics, whether you’re building a solution in-house or going through a third-party vendor. This will set you and your entire team up for success.
- KPIs to improve: This could be your NPS score, star rating, or response time on your help desk. Define a specific goal in order to understand what data channels you need to analyze and how you will measure the performance and ROI of your solution.
- Data channels to analyze: Consider what sources of customer data are available for your analysis, like surveys or call transcripts. Based on the goal you define, you might include data from multiple sources. Your text analytics solution will have to support multichannel analysis in this case.
- Integrations with your tech stack: Especially with multiple data sources, think about how data will flow into your text analytics software. Manually exporting and importing data is not the most efficient process. Native integrations through APIs are ideal for robust and real-time analysis.
- Internal resources: If you’re choosing build over buy for your text analytics solution, take into account the developers in your teams and their experience with AI. In order to get executive buy-in, you’ll need to justify the efforts (time and money) to build your proposed in-house solution.
- Cost of organizational change: The biggest obstacle businesses face is lack of adoption. It’s extremely important to test your potential solution in your organization with a free trial or proof of concept, to assess if your end users are comfortable incorporating it into their workflows.
- Budget costs of build vs buy: A huge oversight when building text analytics in-house is thinking that your software is a static instance. A small script does not scale into a full text analytics solution, in fact, it has to evolve over time with your business assuming the maintenance costs.
That about sums up what you need to know about text analytics software, from what kinds of software are out there to support your text analysis, to the big question of build vs buy and what to consider in a solution – in terms of adoption and pitching it to upper management.
Keatext can be your text analytics solution
If you found this post useful, you might find our platform even more so! Here are a few points about how Keatext is made to support you and your analysis workflow:
- AI-driven text analytics: A text analytics software is only as good as the quality of insights it can uncover for your business. Our core text analytics engine is powerful enough to learn and adapt to the unique context of your data.
- Automated, ready-to-share reports: Keatext aggregates your top opportunities for improvement in one easy PDF. You can instantly export a summary of these insights to share directly with the right business units.
- Recommendations: Thanks to an intelligent integration, we built a way to use Keatext as a knowledge base for OpenAI’s GPT to generate natural language recommendations on how to improve areas of your business that have the most impact on your customer satisfaction.
- Dashboard visualizations: Customize your dashboards with flexible widgets like a pie chart, sentiment score, heatmap, time series, and more.
A lot of the work we’re doing is to automate the activities involved in closing the loop with customers beyond the analysis of data, such as visualizing insights, preparing recommendations, and building and sharing reports. At Keatext, supporting people like you in your everyday work is always on our minds as we continue to build our platform. If you believe in your text analysis program, we believe in you too!





